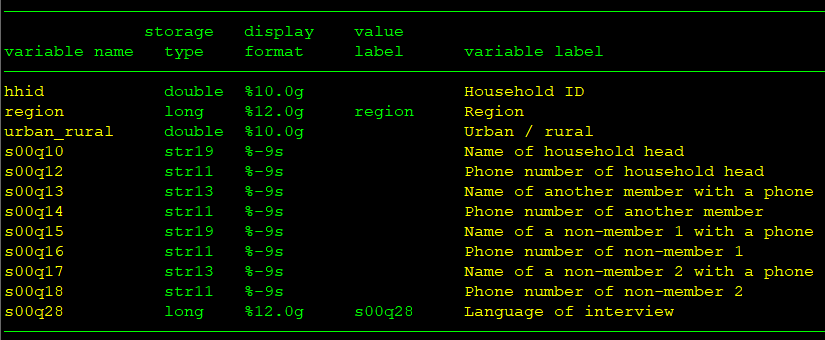
Household data
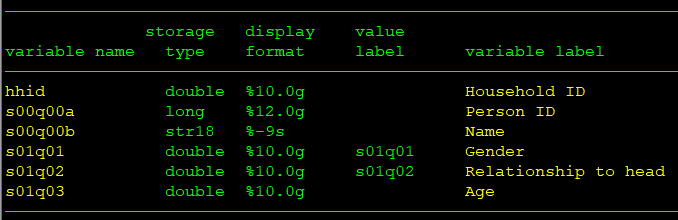
Member data
Set up project parameters
* FOLDERSlocal proj_dir "" // folder where all project files are locatedlocal input_dir "`proj_dir'" // folder where input files are found. For example: "`proj_dir'/input/"local output_dir "`proj_dir'" // folder where output files are found. For example: "`proj_dir'/output/"* FILES* input:local hhold_file_in "households.dta" // household file for this demolocal member_file_in "members.dta" // members file for this demo* output:local hhold_file_out "cati_panel_round1.tab" * file name = questionnaire variable * to find this name: * - open the questionnaire in Designer * - click on SETTINGS * - copy value from Questionnaire variablelocal number_file_out "numbers.tab" * NUMBERS ROSTER * file name = roster ID in Designerlocal member_file_out "members.tab" * MEMBERS ROSTER * file name = (first) roster ID in Designerlocal hhold_file_out "cati_panel_round1.tab" * file name = questionnaire variable * to find this name: * - open the questionnaire in Designer * - click on SETTINGS * - copy value from Questionnaire variable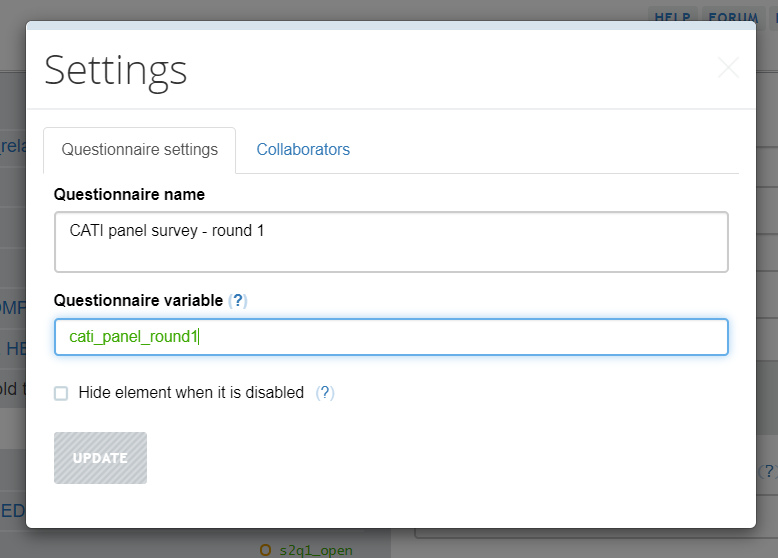
local number_file_out "numbers.tab" * NUMBERS ROSTER * file name = roster ID in Designer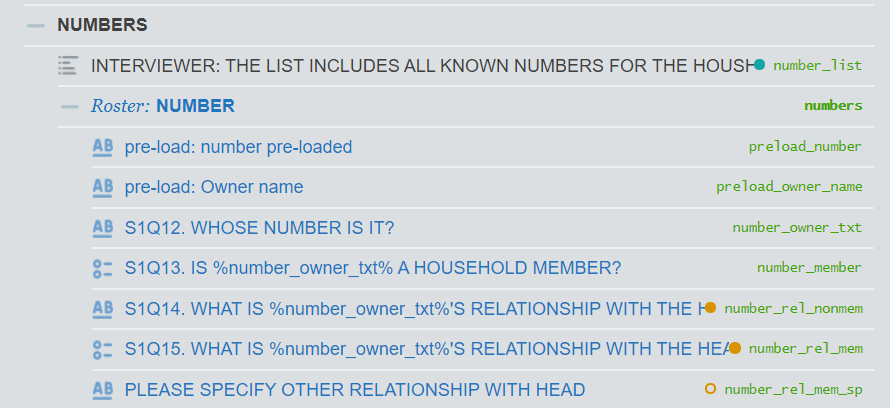
local member_file_out "members.tab" * MEMBERS ROSTER * file name = (first) roster ID in Designer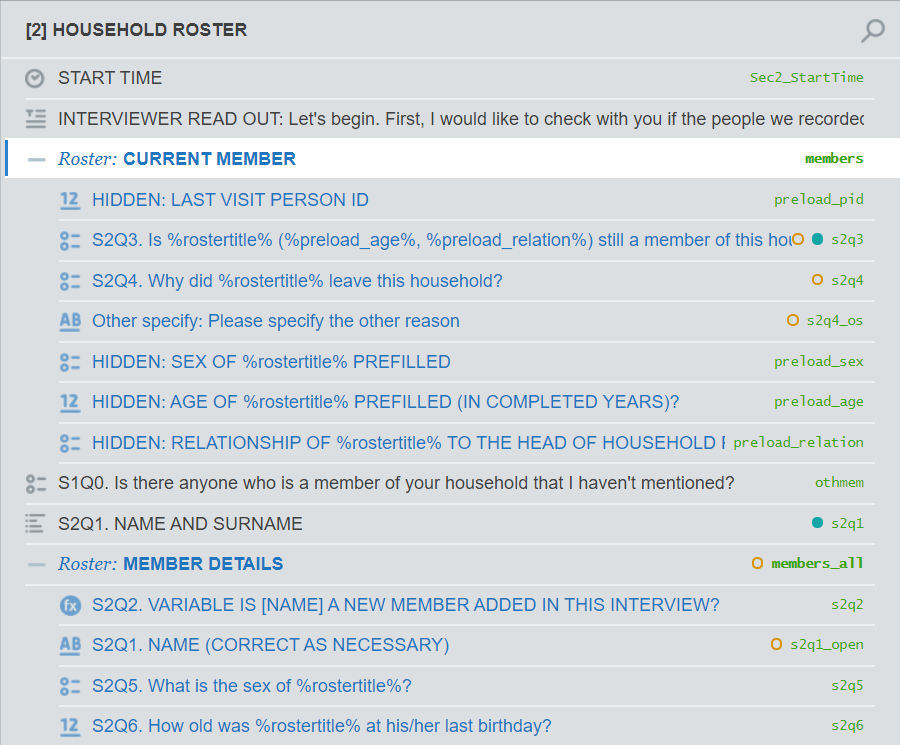
Create roster of numbers
use "`households'", clear* keep necessary variables onlykeep interview__id s00q10 - s00q18* rename variables so that: * - names and numbers have expressive stub names* - contain indices to facilitate reshapingrename (s00q10 s00q13 s00q15 s00q17) /// (name1 name2 name3 name4)rename (s00q12 s00q14 s00q16 s00q18) /// (number1 number2 number3 number4)* reshape so names and numbers, respectively, * inhabit their own columnsreshape long name@ number@, i(interview__id) j(number_id) * retain rows with non-empty contacts onlykeep if (!mi(name) & !mi(number))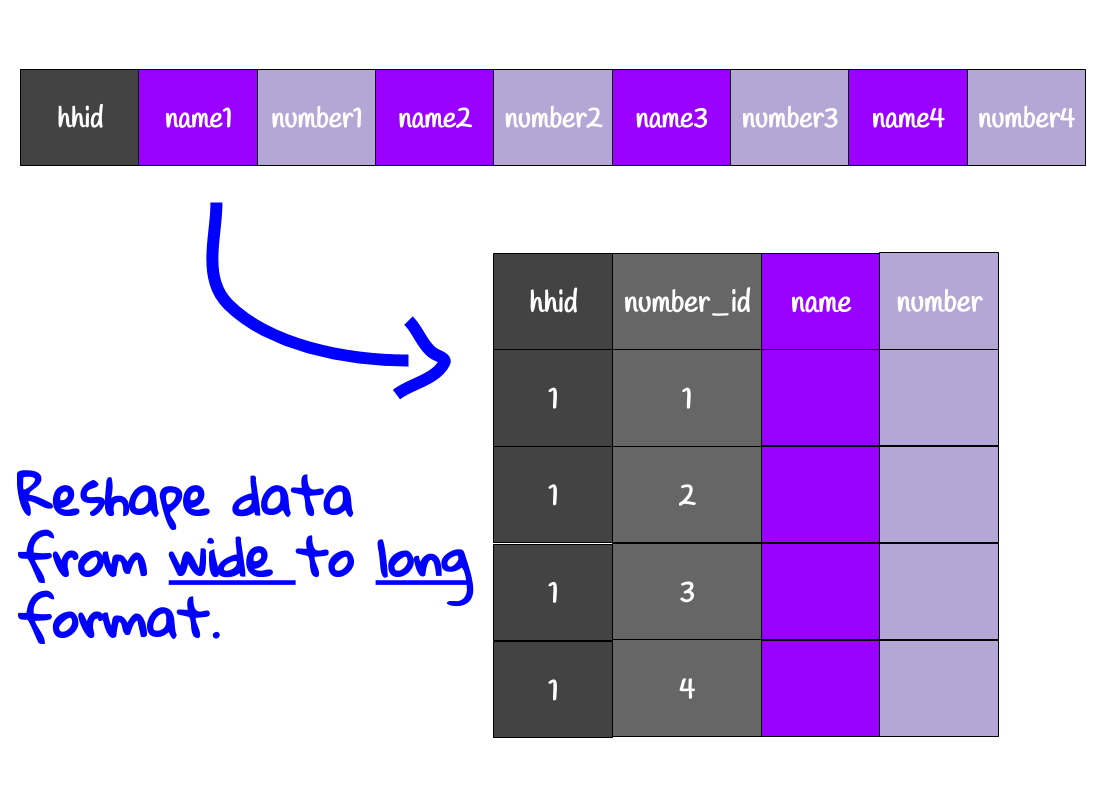
* create variables for preloading* map variables to expected columnsgen number_list = numbergen preload_number = numbergen preload_owner_name = namegen number_owner_txt = name* determine who owns number based on source variable* contacts 1 and 2 are for members* contacts 3 and 4 are for non-membersgen number_member = .replace number_member = 1 if inlist(number_id, 1, 2) replace number_member = 2 if inlist(number_id, 3, 4) * determine relationship to head by source variable* contact 1 is for the household headgen number_rel_mem = .replace number_rel_mem = 1 if (number_id == 1)
* create ID variables* household * interview__id, already in dset, is used by SuSo* contact numbersort interview__id number_idbysort interview__id: gen numbers__id = _n* retain only the necessary variableskeep interview__id numbers__id /// number_list /// preload_number /// preload_owner_name /// number_owner_txt /// number_member /// number_rel_memtempfile numbers_rostersave "`numbers_roster'"
Create list of numbers
use "`numbers_roster'"keep interview__id numbers__id number_list* decrement each index by 1* list questions are 0-indexed in SuSoreplace numbers__id = numbers__id - 1* rename to match list question naming* list questions are composed of:* - core variable name: var* - index of list element: #* - separator: __* that is, elements of the form: var__#rename number_list number_list__* reshape from long roster to wide list* see image at right for intuitionreshape wide number_list__, i(interview__id) j(numbers__id)tempfile numbers_listsave "`numbers_list'"
Create roster of people
use "`members'", clear* Keep only those members that are still part of the household (according to the last survey)* This is most relevant for panel surveys* This may also be applicable for multi-visit cross-sectional surveys* Keep this code only if applicable.keep if still_member == 1
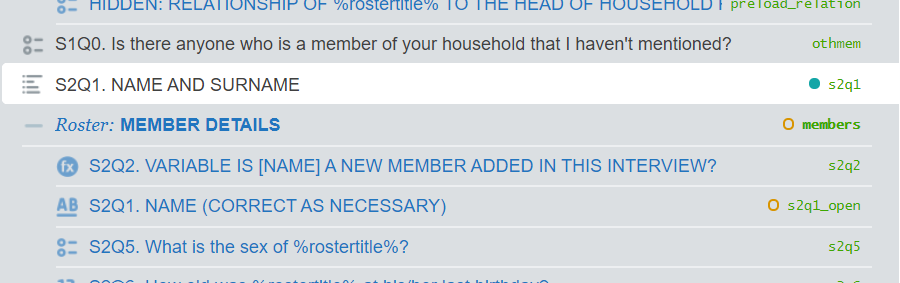
* rename/create variables to match SuSo// panel person IDgen preload_pid = s00q00a// namerename s00q00b s2q1gen s2q1_open = s2q1// sexrename s01q01 s2q5gen preload_sex = s2q5// agerename s01q03 s2q6gen preload_age = s2q6// relationshiprename s01q02 s2q7gen preload_relation = s2q7* sort by household and person IDs* not stricly needed; just neatersort interview__id s00q00a* create a new sequential person identifier* why?* SuSo needs a person ID that:* - starts with 0* - is sequential* - has no gaps in sequence* This ensures that member list (next slide) is of correct form* Person ID may not be sequential for a few reasons:* - Members may have been dropped (earlier this slide)* - Gaps exist because of data generation processbysort interview__id: generate members__id = _n
keep interview__id members__id /// IDs preload_pid /// panel ID preload_sex /// sex preload_age /// age preload_relation /// relationship s2q1 s2q1_open /// name s2q5 /// sex s2q6 /// age s2q7 /// relationshiptempfile members_rostersave "`members_roster'"Create household-level data
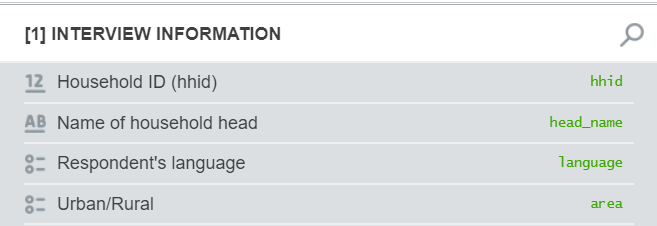
use household.dta, clear* rename variables to match SuSorename s00q10 head_namerename urban_rural arearename s00q28 language* keep only those needed by SuSo* since SuSo does not know how to* handle extra variableskeep interview__id hhid head_name area languagetempfile householdssave "`households'", replaceAdd lists to the household-level data
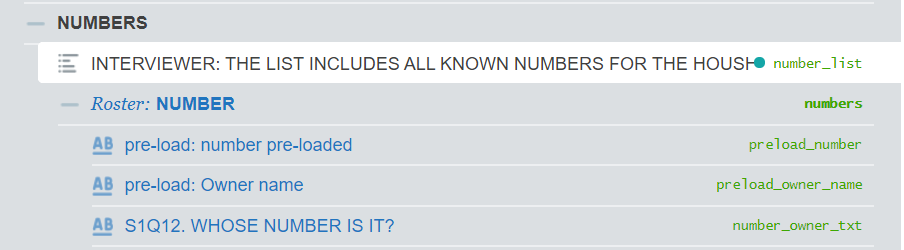
use "`households'", clear* add list questions to household file// members listmerge 1:1 interview__id using "`members_list'", nogen noreport assert(3) keep(3)// numbers listmerge 1:1 interview__id using "`numbers_list'", nogen noreport assert(3) keep(3)tempfile households_plus_listssave "`households_plus_lists'"Create list of variables to protect
* create a data set of following form:* | variable__name |* | --------------- |* | "var1" |* | "var2" |* create empty data set with 2 observationsclearset obs 2* populate those observations with names of* variables whose preloaded values to protect* typically, these are roster triggers* like the list questions belowgen variable__name = ""replace variable__name = "s2q1" in 1replace variable__name = "number_list" in 2tempfile protected_varssave "`protected_vars'"Save to tab-delimited format
* HOUSEHOLD LEVEL* file name = questionnaire variable* to find this name: * - open the questionnaire in Designer* - click on SETTINGS* - copy value from Questionnaire variableuse "`households'", clearoutsheet using cati_panel_round1.tab, /// nolabel /// save values, not labels noquote /// no quotes for strings replace
* NUMBERS ROSTER* file name = roster ID in Designeruse "`numbers'", clearoutsheet using numbers.tab, /// nolabel /// save values, not labels noquote /// no quotes for strings replace
* MEMBERS ROSTER* file name = (first) roster ID in Designeruse "`members'", clearoutsheet using members.tab, /// nolabel /// save values, not labels noquote /// no quotes for strings replace
* VARIABLES TO PROTECT FROM EDITING* file name = name system expects: protected__variablesuse "`protected_vars'", clearoutsheet using protected__variables.tab, noquote replace